import numpy as np # Общепринятый псевдоним
print(np.__version__)2.2.4Numpy (Numerical python) - мощная и высокопроизводительная библиотека для математических вычислений и линейной алгебры. Секрет её производительности в том, что она является оберткой для функций, написанных на языке C. На типах данных, функциях и принципах, заложенных в этой библиотеке, основываются основные библиотеки для анализа данных на Python, такие как pandas, scipy. Numpy имеет свой официальный сайт, хорошую документацию и обучающие материалы с примерами. Библиотека легко устанавливается как через conda,
conda install -c conda-forge numpyтак и через pip.
pip install numpyЧтобы проверить корректность установки, выполните следующий код.
import numpy as np # Общепринятый псевдоним
print(np.__version__)2.2.4Основным типом данных в numpy является гомогенный многомерный массив (numpy.ndarray или array). Гомогенный - состоящий из объектов одного типа. Создать такой массив можно из просто списка python. Следующий пример иллюстрирует основные атрибуты объекта ndarray.
example = np.array([[1,2,3,4,5],[6,7,8,9,0]])
1print(f"Количество осей {example.ndim}")
2print(f"Форма массива {example.shape}")
3print(f"Количество элементов {example.size}")
4print(f"Тип элементов {example.dtype}")
5print(f"Размер элемента в байтах {example.itemsize}")Типы данных отличаются от встроенных в Python. Это никак не влияет напрямую на их использование, и с этмими типами можно совершать всё те же арифметические и логические операции. Язык С, на котором написана библиотека, является компилируемым языком с строгой типизацией, что позволяет значительно ускорить расчеты. Типы dtype используются только внутри библиотеки.
Рассмотрим способы создания массивов, кроме приведения типов.
# Массив нельзя создать следующим образом
# a = np.array(1, 2, 3, 4)
1a = np.zeros((3, 4))
2b = np.ones((2, 3, 4), dtype=np.int16)
3c = np.arange(10, 30, 5)
4d = np.linspace(0, 2, 9)
print(a)
print(b)
print(c)
print(d)Кроме этого, numpy предоставляет функционал генеарции случайных массивов из различных распределений.
rng = np.random.default_rng()
1a = rng.integers(0,10,5)
2b = rng.uniform(1,10,5)
3c = rng.normal(10, 5, 2)Базовые арифметические и логические операции выполняются над массивами поэлементно. Иначе говорят, что эти операции векторизированы. Чтобы понять, что это означает, приведем простой пример: допустим над надо сложить два списка.
Пример реализации на чистом питоне.
a = [1,2,3,4,5]
b = [1,2,3,4,5]
c = []
for i in range(len(a)):
c.append(a[i] + b[i])
c = list(map(lambda i: a[i] + b[i], range(len(a)))) # аналогичное решение в одно строкуРешение на numpy выглядит просто и элегантно.
a = np.array([1,2,3,4,5])
b = np.array([1,2,3,4,5])
c = a + b
print(c)[ 2 4 6 8 10]Также и с логическими операциями
a = np.array([20, 30, 40, 50])
a < 35array([ True, True, False, False])Простое умножение матриц будет работать поэлементно. Если вам нужно перемножить матрицы по математическому определению умножения матриц, то для этого есть оператор @ или функция dot.
A = np.array([[1, 1],
[0, 1]])
B = np.array([[2, 0],
[3, 4]])
print(A * B) # elementwise product
print(A @ B) # matrix product
print(A.dot(B)) # another matrix product[[2 0]
[0 4]]
[[5 4]
[3 4]]
[[5 4]
[3 4]]Для многомерных массивов, можно выполнять аггрегирующие операции вдоль некоторой оси (минимум, максимум, среднее, сумма и т.п.)
Кроме базовых операций в numpy определены так называемые универсальные математические функции: синус, косинус, экспонента, квадратный корень и многое другое.
b = np.arange(12).reshape(3, 4)
print(np.sin(b))
print(np.exp(b))[[ 0. 0.84147098 0.90929743 0.14112001]
[-0.7568025 -0.95892427 -0.2794155 0.6569866 ]
[ 0.98935825 0.41211849 -0.54402111 -0.99999021]]
[[1.00000000e+00 2.71828183e+00 7.38905610e+00 2.00855369e+01]
[5.45981500e+01 1.48413159e+02 4.03428793e+02 1.09663316e+03]
[2.98095799e+03 8.10308393e+03 2.20264658e+04 5.98741417e+04]]Принципы индексации и выбора элементов для массивов numpy такие же, как и для списков python. Преимущество numpy в том, что он расширяет эти правила на многомерный случай, позволяя их применять вдоль каждой оси, перечисляя интервалы через запятую.
b = np.arange(12).reshape(3, 4)
print(b[-2, 0:2]) numpy предоставляет функционал для изменения форма массивов. Уже использовалась выше функция reshape. Она меняет по возможности форму массива. Например arange создает массив формой (12) и с помощью reshape преобразуем его в двумерной с формой 3 на 4.
reshape используют для создания многомерных массивов или для манипуляцийс многомерными массивами. Если вам необходимо “спрямить” матрицу, т.е. сделать из многомерного массива одномерный, существует функция ravel.
a = np.arange(12).reshape(3, 4)
b = a.ravel()
print(a)
print(b)Важный момент: присвоение существующего массива другой переменной, не создает копии массива. В переменной всего лишь хранится адрес на этот массив. Поэтому, если вы измените знаение по одной переменной, то вдругой оно также изменится. Для создания копии массива используйте метод copy.
sys.getsizeof).Pandas - библиотека для языка программирования Python для работы с табличными данными. Это мощный инструмент в арсенале аналитика данных, так как она может работать с большинством современных форматов данных, представляя их в виде таблицы. Pandas владеет большим функционалом работы с таблицами и позволяет делать с ними всё что угодно: чтение, запись, фильтрацию, математические операции, расчет статистики, визуализацию данных и многое другое. Библиотека имеет исчерпывающую документацию и собственные обучающие материалы на своём официальном сайте.
Основный тип данных, используемый в этой библиотеке - датафрейм (DataFrame). Визуальная схема представления этого типа данных представлена на Figure 20.1. Датафрейм - двумерная таблица, состоящая из строк и столбцов. Столбцы имеют свои названия (columns) и строки имеют свои названия (index).

Каждый столбец представляеют собой серию (Series). Визуальная схема представления этого типа данных представлена на Figure 20.2. Серия не имеет имени столбцов, но имеет имена строк (индексы) и может иметь собственное имя. Серии являются надстройкой над numpy.array, поэтому сохранили ряд атрибутов от него: например общий тип данных (dtype).

Установить библиотеку pandas можно как через окружение conda,
conda install -c conda-forge pandas openpyxl #openpyxl зависимость для работы с Excelтак и через менеджер пакетов pip
pip install pandasЧтобы начать работу с этой библиотекой, необходимо её импортировать.
import pandas as pd
print(pd.__version__)2.2.3pd - это общепринятый псевдоним библиотеки
Для дальнейшей работы скачаем пример таблицы. Данные о пассажирах Титаника являются классическим примером в обучающих материалах по анализу данных и машинному обучению. Данные необходимо скопировать, перейдя по ссылке, в Excel и сохранить в формате csv.
.csv - comma-separated values - формат файлов, где значения в разных столбцах разделены друг от друга запятой. На самом деле разделителем может быть любой символ, но общепринятые это запятая, точка с запятой или табуляция.
Библиотека pandas может работать с большим количеством форматов и чтобы прочитать их, она содержит функции, чье имя подчинено формату read_*, где вместо звездочки имя формата. Эти функции лежат вне класса в самом модуле и возвращают объект DataFrame. Чтобы убедиться в правильности считывания, вызовем функцию head класса DataFrame. Она возвращает первые n строк таблицы.
titanic = pd.read_csv("data/titanic.csv", sep = ",")
titanic.head()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
Pandas может сохранит датафрейм в любой формат, с которым умеет работать. Для этого существуют функции, чье имя подчинено формату to_*, где вместо звездочки имя формата. Общая схема работы представлена на Figure 20.3.
# нужна библиотека openpyxl
titanic.to_excel("data/titanic.xlsx", sheet_name="passengers", index=False)
# sheet_name - имя листа книги Excel
# index - Флаг, сохранять ли индекс датафрейма. Часто это не нужно

Схема манипуляции представлена на Figure 20.4. Индексация по строкам и столбцам в датафрейме осуществляется с помощью квадратных скобок. Чтобы выбрать отдельный столбец, достаточно указать его имя.
ages = titanic["Age"]Один столбец - это серия.
type(titanic["Age"])pandas.core.series.SeriesОбъекты pandas как и массивы numpy содержат в себе атрибут формы
titanic["Age"].shape(891,)Чтобы выбрать несколько столбцов, необходимо передать список их имён.
age_sex = titanic[["Age", "Sex"]]
age_sex.head()| Age | Sex | |
|---|---|---|
| 0 | 22.0 | male |
| 1 | 38.0 | female |
| 2 | 26.0 | female |
| 3 | 35.0 | female |
| 4 | 35.0 | male |
Тогда возвращаемый тип уже будет датафреймом.
type(titanic[["Age", "Sex"]])pandas.core.frame.DataFrame
Схема фильтрации строк показана на Figure 20.5. pandas поддерживает логическую индексацию. Следовательно, вместо передачи номеров конкретных строк, мы можем фильтровать их по условию. Например, нам нужны все пассажиры старше 35 лет.
above_35 = titanic[titanic["Age"] > 35]Операция сравнения является векторизированной, поэтому Выражение titanic["Age"] > 35серию чисел с возрастом превращает в серию логических значений. Таким образом, остаются только те строки, где значение равно True. pandas поддерживает все обычные операции сравнения.
titanic["Age"] > 350 False
1 True
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: boolЧтобы составить сложные логические высказывания, нужно воспользоваться специальными переопределенными операциями (переопределены битовые операции).
& - конъюнкция
| - дизъюнкция
~ - инверсия
class_23 = titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
class_23.head()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 3 | 1 | 3 | Heikkinen, Miss Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 7 | 8 | 0 | 3 | Palsson, Master Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
Особые случаи из себя представляют проверка на наличие в списке и проверка на пропущенное значение. Для них существуют специальные функции isin() и notna(). Предыдущий пример можно переписать более изящно.
class_23 = titanic[titanic["Pclass"].isin([2, 3])]
class_23.head()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 3 | 1 | 3 | Heikkinen, Miss Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 7 | 8 | 0 | 3 | Palsson, Master Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
Оставить только строки с непропущенными значениями можно с помощью функции notna()
age_no_na = titanic[titanic["Age"].notna()]
age_no_na.shape(714, 12)
Схема совместной фильтрации строк и столбцов показана на Figure 20.6. Для неё исть два класса функций локализации loc и iloc. Функция iloc работает исключительно с порядковыми номерами строк и столбцов. Если хотя бы для строк и для столбцов используется имя или условие, необходимо использовать функцию loc.
# имена взрослых
adult_names = titanic.loc[titanic["Age"] > 35, "Name"]
adult_names.head()1 Cumings, Mrs. John Bradley (Florence Briggs Th...
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss Elizabeth
13 Andersson, Mr. Anders Johan
15 Hewlett, Mrs. (Mary D Kingcome)
Name: Name, dtype: objectВыбор строк с 10 по 25 и с 3 по 6 колонку
titanic.iloc[9:25, 2:5]| Pclass | Name | Sex | |
|---|---|---|---|
| 9 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female |
| 10 | 3 | Sandstrom, Miss Marguerite Rut | female |
| 11 | 1 | Bonnell, Miss Elizabeth | female |
| 12 | 3 | Saundercock, Mr. William Henry | male |
| 13 | 3 | Andersson, Mr. Anders Johan | male |
| 14 | 3 | Vestrom, Miss Hulda Amanda Adolfina | female |
| 15 | 2 | Hewlett, Mrs. (Mary D Kingcome) | female |
| 16 | 3 | Rice, Master Eugene | male |
| 17 | 2 | Williams, Mr. Charles Eugene | male |
| 18 | 3 | Vander Planke, Mrs. Julius (Emelia Maria Vande... | female |
| 19 | 3 | Masselmani, Mrs. Fatima | female |
| 20 | 2 | Fynney, Mr. Joseph J | male |
| 21 | 2 | Beesley, Mr. Lawrence | male |
| 22 | 3 | McGowan, Miss Anna "Annie" | female |
| 23 | 1 | Sloper, Mr. William Thompson | male |
| 24 | 3 | Palsson, Miss Torborg Danira | female |
Попробуйте применить полученные знания для работы с собственными таблицами (не важно, научные или житейские).
В анализе данных крайне важный этап эта их визуализация. Визуальный анализ может многое рассказать о данных, чего не расскажут самые хитрые метрики. Занимательный пример, иллюстрирующий данный тезис, был придуман английским математиком Ф. Энскомбом. Он придумал 4 набора данных, которые имеют одни и те же значения основных описательных статистик, но совершенно по-разному устроенных. Более подробно вы можете прочитать об этом здесь. Базовый пакет для визуализации в Python - Matplotlib. Библиотека имеет исчерпывающую документацию и собственные обучающие материалы на своём официальном сайте. С ней сложно строить комплексные графики, состоящих из нескольких типов графиков, но на нем основываются другие пакеты, которые призваны облегчить эту задачу. Например, библиотека seaborn, которая содержит matplotlib и работает с ним в связке, содержит некоторый набор комплексных визуализзаций и приспособлена для с работы с pandas. matplotlib также легко устанавливается через conda,
conda install -c conda-forge matplotlibтак и через pip.
pip install matplotlibЧтобы проверить корректность установки, выполните следующий код.
import matplotlib
print(matplotlib.__version__)3.10.1Основные элементы графика представлены на Figure 20.7.
Полотно, на котором размещаются элементы графика, называется figure. На нем может быть от 0 до большого количество подсюжетов (subplots). Сюжет это то, что мы обычно подразумеваем под графиком, т.е. некоторой совокупности кривых в некоторой координатной сетке. У каждого сюжета есть заголовок (title) и оси (axes). Оси - основные объекты для управления сюжетом. С их помощью мы наносим на график данные, которые могут быть в виде линий, точек (markers) или геометрических фигур. Оси имеют подписи (labels), значения на осях (ticks), которые задают основную цену деления (major ticks) и малую цену деления (minor ticks). График может иметь сетку (grid) и легенду (legend), повествующую об изображенных данных. Все элементы управления графиком расположены в подмодуле pyplot, поэтому часто импортируют только его под псевдонимом plt.
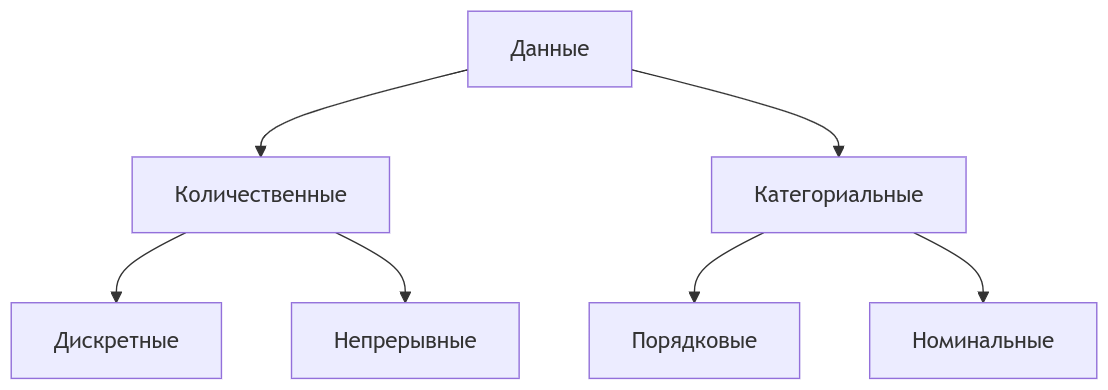
Для визуализации разных типов данных используют разные графики. У matplotlib на офицальном сайте есть галерея графиков с примерами кода. Для начала разговора о видах графиков определим типы данных с точки зрения их анализа. Классификация представлена на Figure 20.8
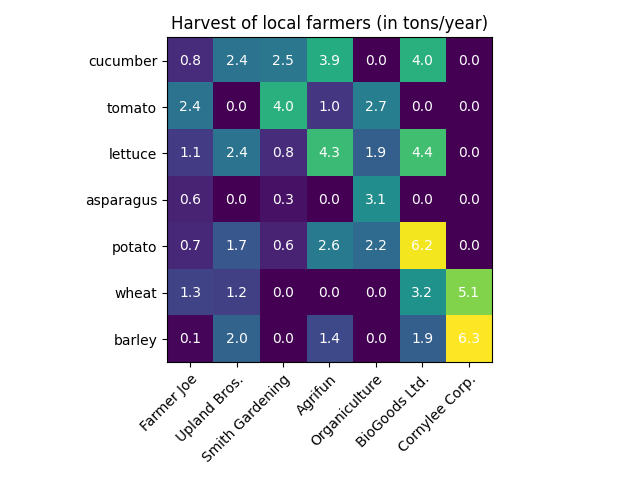
Кроме типа данных необходимо понимать цель - что мы хотим им показать и количество переменных. Основные цели - показать распределение, зависимость, соотношения. Для визуализации распределений количественных переменных можно использовать гистограммы Figure 20.9, графики плотности (сглаженная гистограмма), “ящики с усами” (boxplots) Figure 20.10, violin plot Figure 20.11. Для визуализации распределения категориальных величин, их соотношения между друг другом можно использовать столбчатые (barplot) Figure 20.12 или круговые (pieplot) диаграммы Figure 20.13. Для отображения зависимостей между двумя количественными переменными используют диаграмму рассеяния (scatter plot) Figure 20.14. Для визуализации зависимости количественной величины от двух категориальных применяют тепловую карту (heatmap) Figure 20.15.
Тип данных, количество переменных, цель графика определяется автором исходя из здравого смысла и вкуса. Это нельзя определять автоматически. Важно помнить, что хоть изначально график может иметь одну, две или три оси, то слоев повествования он может иметь гораздо больше. Дополнительную смысловую нагрузку можно превносить с помощью цвета, типа точек или линий, сочетания нескольки х видов графика на одном, дополнительными треками и другими параметрами, изложенными в документации. Такой график можно нарисовать один раз в графическом редакторе, но это очень долго и менять что-то в нем будет очень мучительно, поэтому визуализация по данным с помощью кода выигрывает. Такой график строится быстро и построит правильный график для любых одинаково устроенных данных, т.е. написанный код можно использовать много раз.
Для начала разберем простой школьный пример - построения графика синуса аргумента на одном периоде.
1import matplotlib.pyplot as plt
import numpy as np
2x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x)
3fig, ax = plt.subplots()
4ax.plot(x, y, color = "red", marker = "o")
5plt.show()
Построим другой тип графиков - возьмем данные с прошлого занятия и визуализируем соотношение выживших к погибшим. Это категориальная переменная, поэтому построим столбчатую диаграмму.
1import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv("data/titanic.csv")
2plt.style.use('default')
# make data:
counts = data["Survived"].value_counts(dropna = False)
x = counts.index
y = counts
# plot
fig, ax = plt.subplots()
3ax.bar(x, y, width=0.5, color=["red","green"], linewidth=0.7, tick_label = ["Погибший","Выживший"])
4ax.set_title("Статус пассажира")
5ax.set(xticks=[0,1])
plt.show()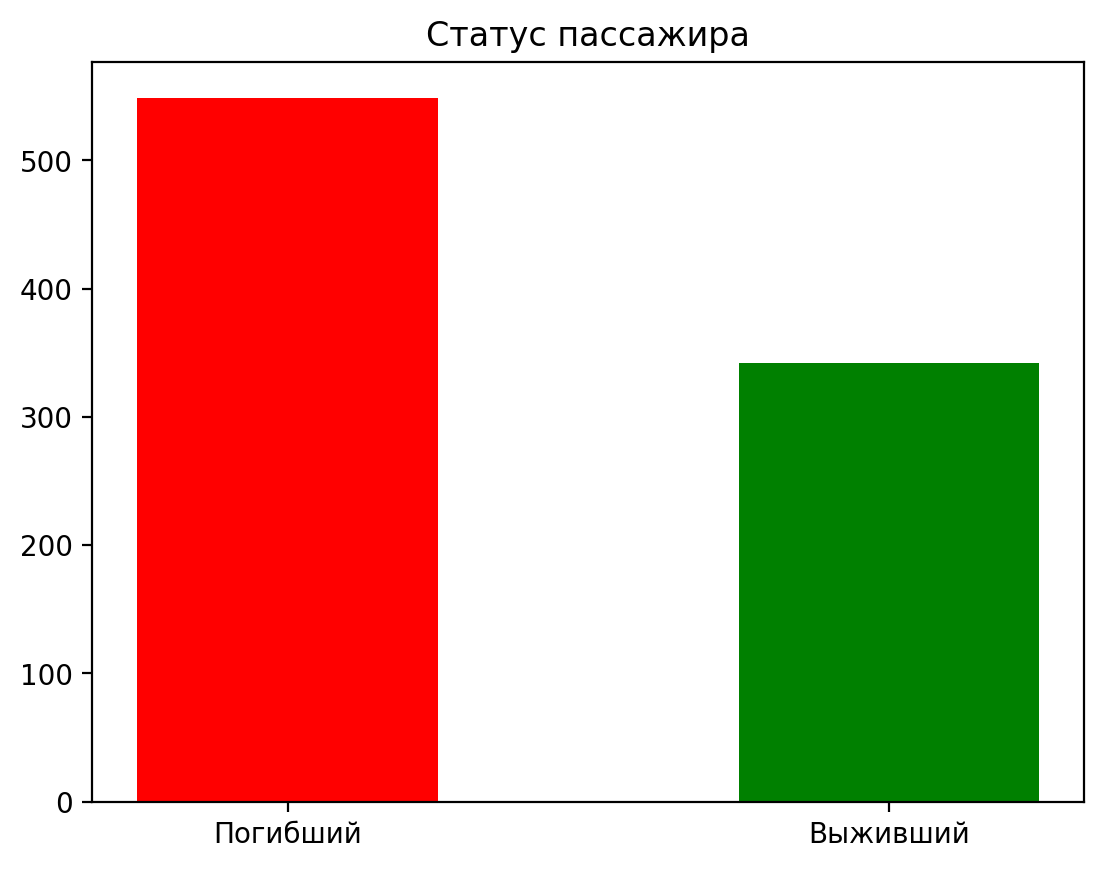
Здесь мы с помощью цветов сделали наш график интуитивно легче читаемым.
Следующий примером мы хотим понять сопоставимость методов измерения концентрации интерлейкина-6. Концентрации интерлейкина-6 были измеряны в выборке образцов плазмы крови больных COVID-19 и контрольных образцов. В идеале все точки должны лежать на диагонали. Кроме того, нанесем слой информации о том, к какой группе по степени тяжести заболевания относится образец.
1import matplotlib.pyplot as plt
import pandas as pd
elisa_data = pd.read_excel(r"data/results_xmap_and_vector.xlsx", engine = "openpyxl")
death = elisa_data.loc[elisa_data["Outcome"] == "смерть", :]
severe = elisa_data.loc[elisa_data["Outcome"] == "тяжелый", :]
moderate = elisa_data.loc[elisa_data["Outcome"] == "средний", :]
control = elisa_data.loc[elisa_data["Outcome"] == "здоровый", :]
2fig, ax = plt.subplots(figsize = (8,6))
3ax.scatter(x = "ELISA, pg/ml", y = "xMAP, pg/ml", data = death)
ax.scatter(x = "ELISA, pg/ml", y = "xMAP, pg/ml", data = severe)
ax.scatter(x = "ELISA, pg/ml", y = "xMAP, pg/ml", data = moderate)
ax.scatter(x = "ELISA, pg/ml", y = "xMAP, pg/ml", data = control)
4ax.set_xlabel("ELISA, pg/ml")
ax.set_ylabel("xMAP, pg/ml")
ax.set_title("IL-6 in human plasma")
5ax.legend(labels = ["смерть","тяжелый","средний","здоровый"])
6fig.tight_layout()
7fig.savefig("images/example.png")
plt.show()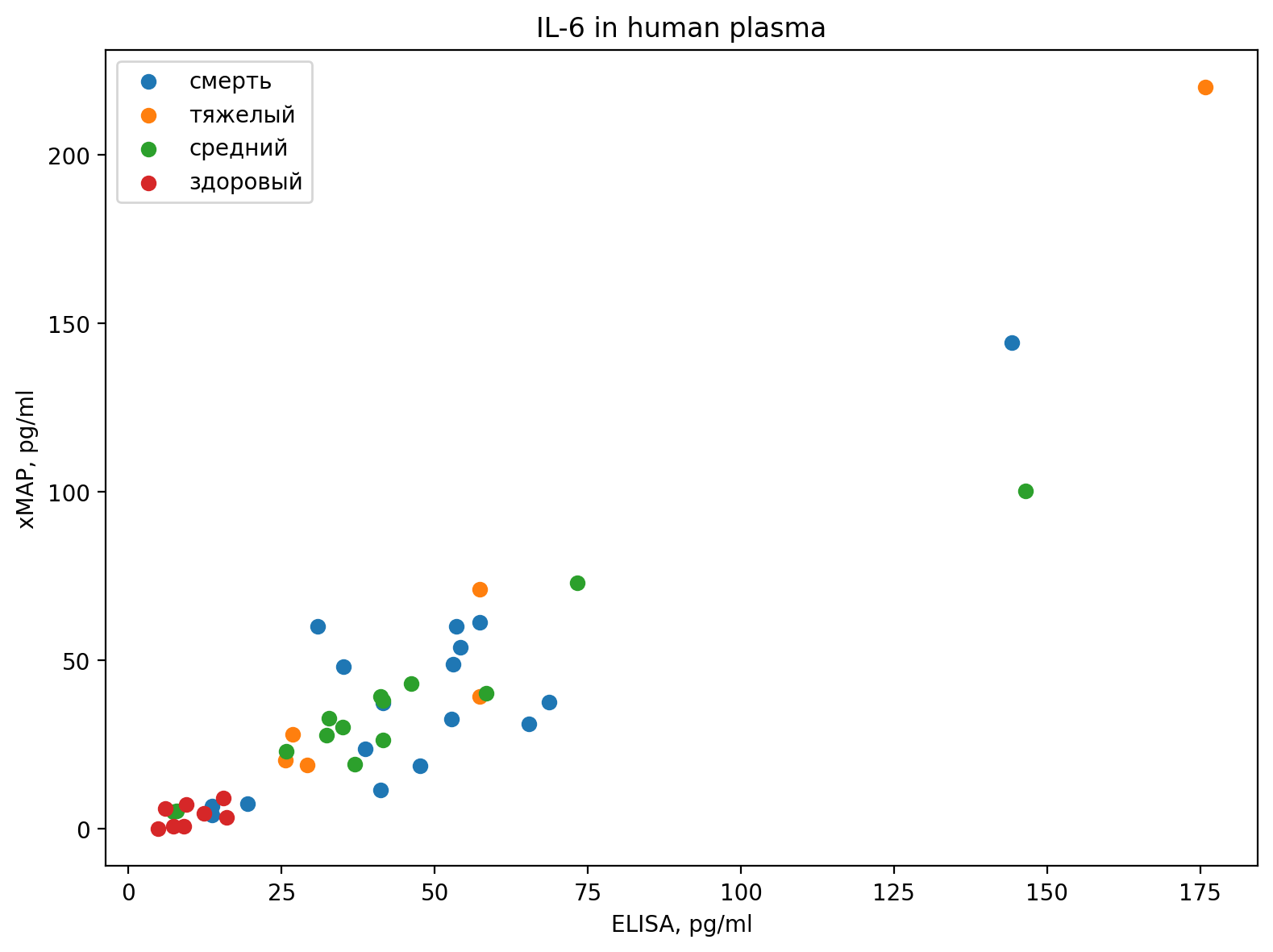
Возьмите датасет о пассажирах Титаника с прошлого занятия и постройте следующие три графика
Распределение по возрасту и полу (т.е. ожидается 2 гистограммы возраста на одном графике)
Соотношение выживших/погибших в зависимости от класса билета
Зависимость цены билета от возраста. Дополнительным слоем (цветом или типом маркера) нанесите порт посадки.
Python - самый популярный язык в анализе данных благодаря простоте самого языка и специализированным пакетам. SciPy - пакет для научных вычислений (SciPy - scientific python). Основан на библиотеке numpy и содержит модули для анализа сигналов, линейной алгебры и численных методов математического анализа, анализа изображений, работы с пространственными данными и статистике. Seaborn - библиотека для визуализации, являющаяся обощением и развитием matplotlib и основана на ней. Она содержит функции для построения сложных графиков по таблицам pandas. То, что в matplotlib может занять 10 строчек кода, seaborn сделает за одну. Библиотека по умолчанию строит графики в приятной пастельной палитре морских цветов, за что и получила своё название. Эти библиотеки также имеют свои собственные официальные сайты, продвинутую документацию и обучающие материалы (scipy, seaborn).
Аналитики данных работают в блокнотах Jupyter. Jupyter Notebook - среда разработки, позволяющая выполнять код на основных аналитических языках програмированния (Python, R, Julia, Scala и многие другие) пошагово в ячейках. Таким образом составлять красивые отчеты, которые могут быть интерактивными. Блокноты имеют расшинение .ipynb. Данное пособие также сверстано с помощью Jupyter Notebook. Экосистема Jupyter содержит также программу Jupyter Lab, более продвинутую среду разработки блокнотов, так как дает функционал управления компьютером через командную строку, работу с системой контроля версий и управление плагинами и расширениями, которыми можно делать работу в Jupyter Lab комфортнее и производительней.
Настроим себе окружение для работы: создадим вирутальное окружение conda с именем stat. Пакеты будем брать из канала conda-forge. Для работы нам потребуется:
Указывать numpy и matplotlib не нужно. Они идут как зависимости к перечисленным пакетам и conda позаботится об установки нужной версии этих пакетов.
conda create -n stat -c conda-forge pandas scipy sсikit-learn ipykernel seaborn jupyterlab
conda activate statВ качестве примера мы рассмотрим популярный в обучении машинному обучению набор данных - ирисы Фишера. Это таблица с данными о 150 цветках 3 видов ирисов: щетинистый (Iris setosa), виргинский (Iris virginica), разноцветный (Iris versicolor). Для каждого цветка измерялись:
Импортируем библиотеки и сделаем небольшой маневр по преобразованию данных ириса из внутреннего представления библиотеки scikit-learn в привычный датафрейм.
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
import seaborn as sns
from sklearn import datasets
1iris = datasets.load_iris()
2iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
3iris_df['species'] = iris.target_names[iris.target]
4iris_df.head()| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
Первый этап анализа данных - убедиться, что всё считалось правильно. Для этого как правило смотрят на первые и последние n-строк. Затем необходимо посмотреть на типы данных в столбцах. Мы имеем 4 столбца с числовыми характеристиками, нет пропущенных значений. 1 столбец с строками для обозначения вида цветка.
iris_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KBСледующий этап - описательная статистика. Для числовых характеристик выполняется вызовом одной функции describe.
iris_df.describe()| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
Для качественных характеристик можно посчитать количество записей для каждого класса. Наш датасет идеально сбалансирован. В каждом классе одинаковое количество записей.
iris_df["species"].value_counts()species
setosa 50
versicolor 50
virginica 50
Name: count, dtype: int64Следующий этап - визуализация. Посмотрим на распределения параметров. Чаще всего это делают с помощью гистограмм и “ящиков с усами”. Воспользуемся библиотекой seaborn для быстрого построения графиков.
1fig, ax = plt.subplots(figsize = (8,6))
2sns.boxplot(data = iris_df, x = "species", y = "sepal length (cm)",hue = "species", ax = ax)
3fig.savefig("images/example1.png", dpi = 300)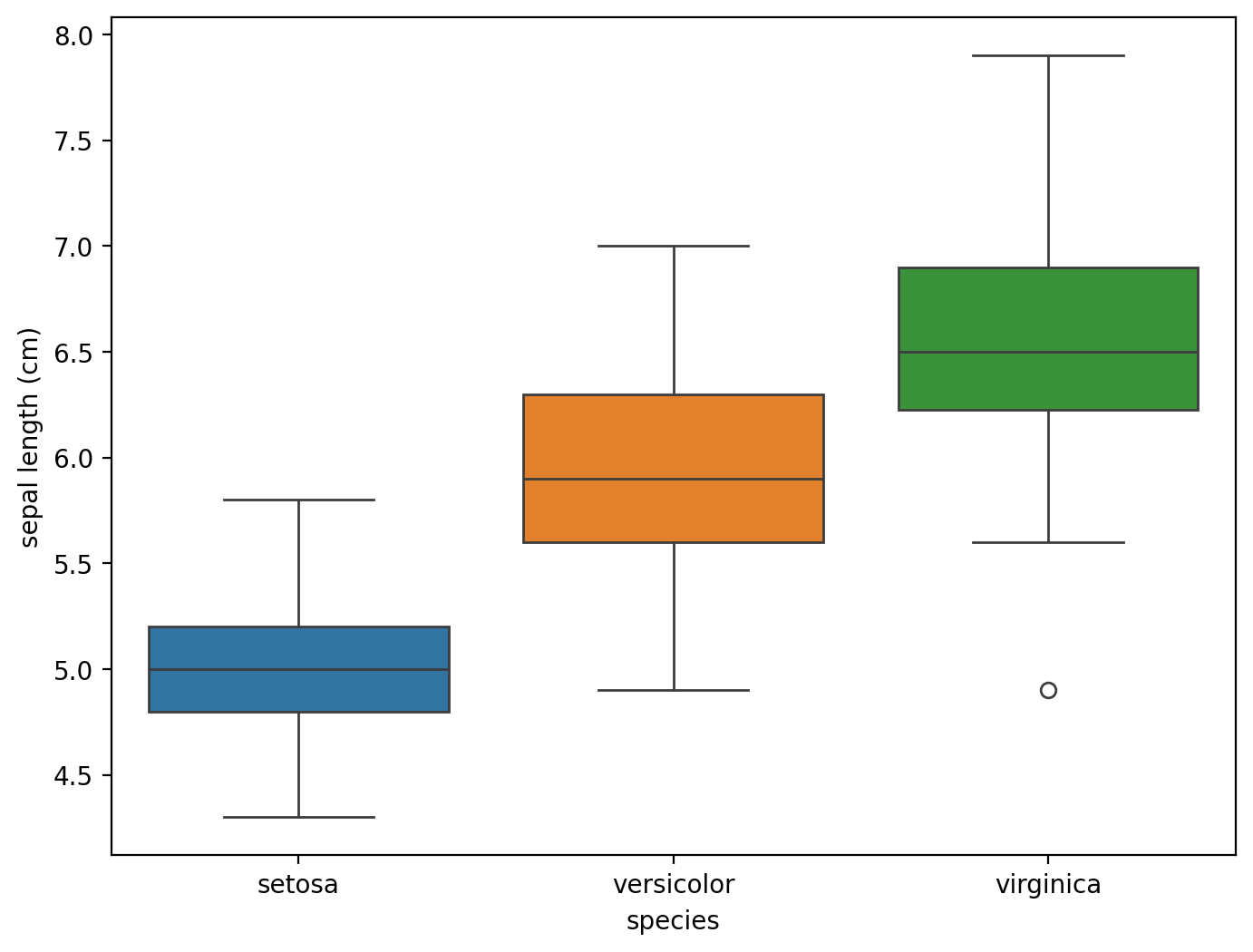
Можно не передавать оси в качестве параметра. Тогда seaborn создаст свой рисунок и на нём изобразит график.
sns.boxplot(data = iris_df, x = "species", y = "petal length (cm)",hue = "species")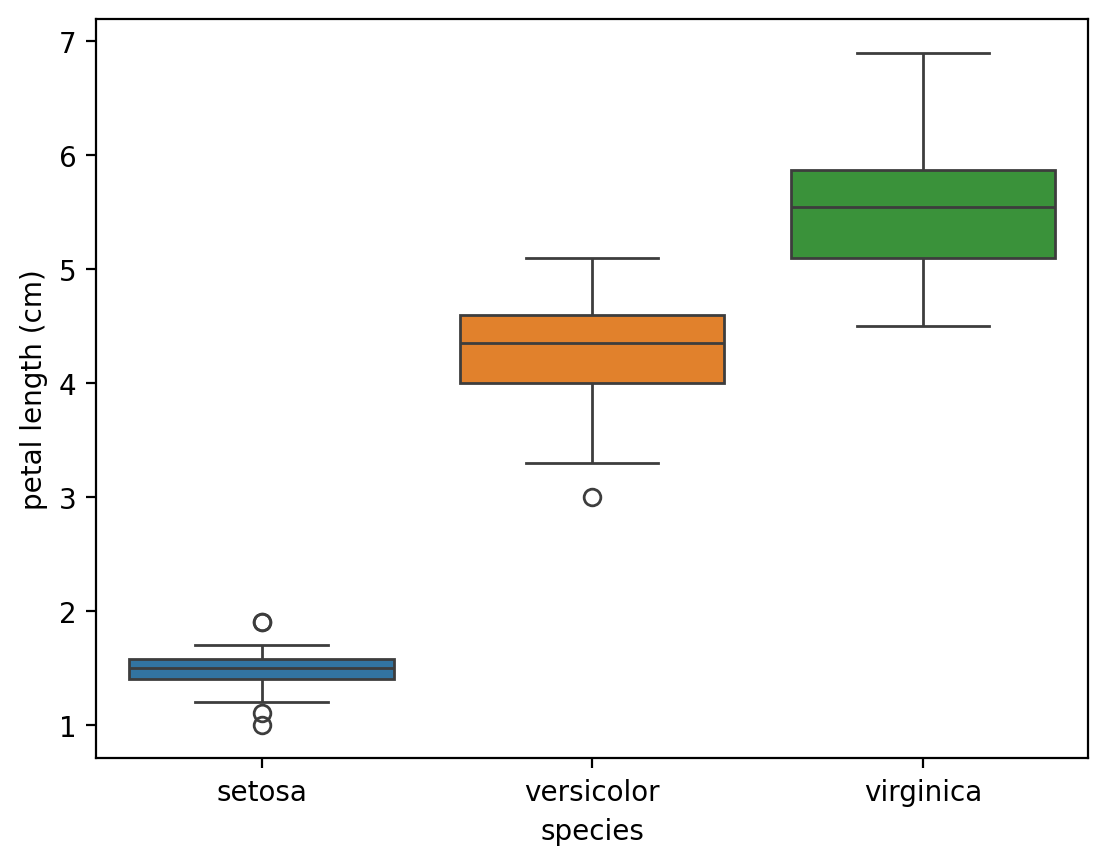
Гистограммы рисовать также легко и приятно. Пример для одного вида. Параметр bins обозначает количество столбиков, на который будет разбит изображаемый интервал.
setosa = iris_df.loc[iris_df["species"] == "setosa"]
sns.histplot(data = setosa, x = "sepal length (cm)", bins = 10)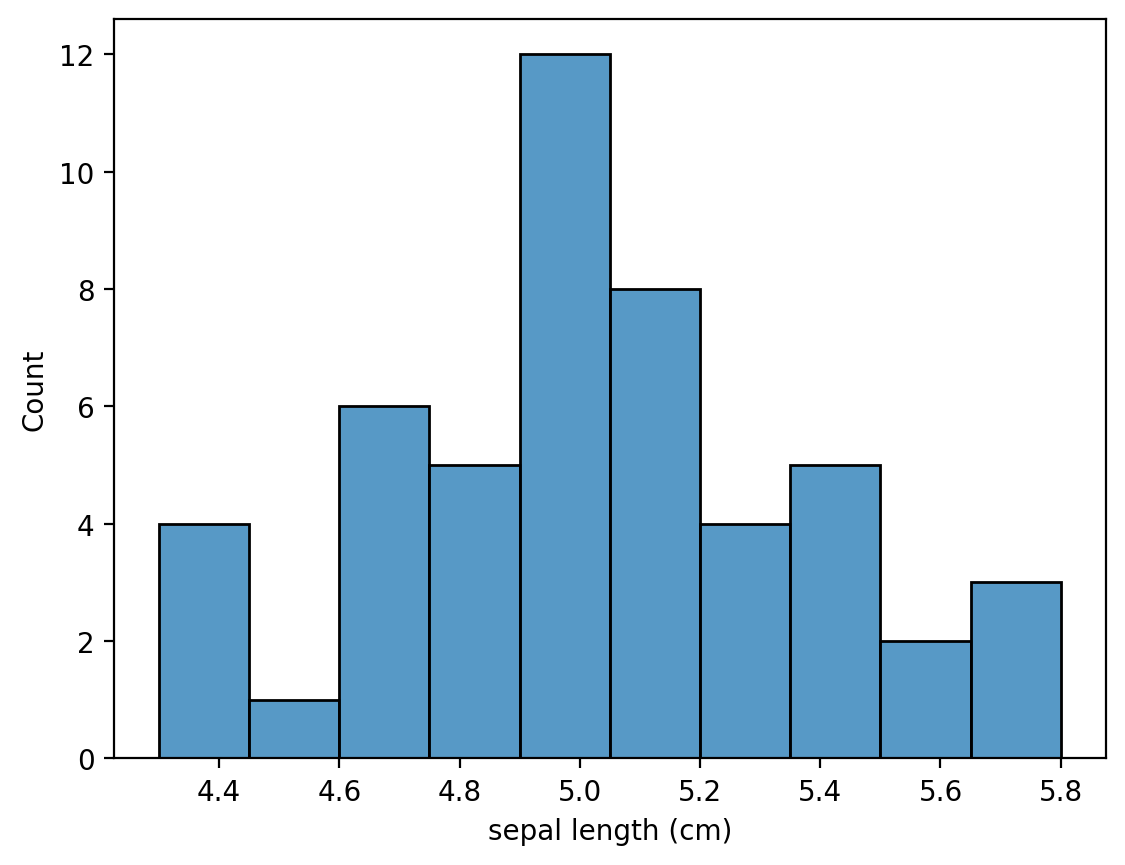
Случай изображения всех классов на одном графике ещё проще. Кроме того, seaborn позаботиться о легенде.
sns.histplot(data = iris_df, x = "sepal length (cm)", hue = "species",bins = 20)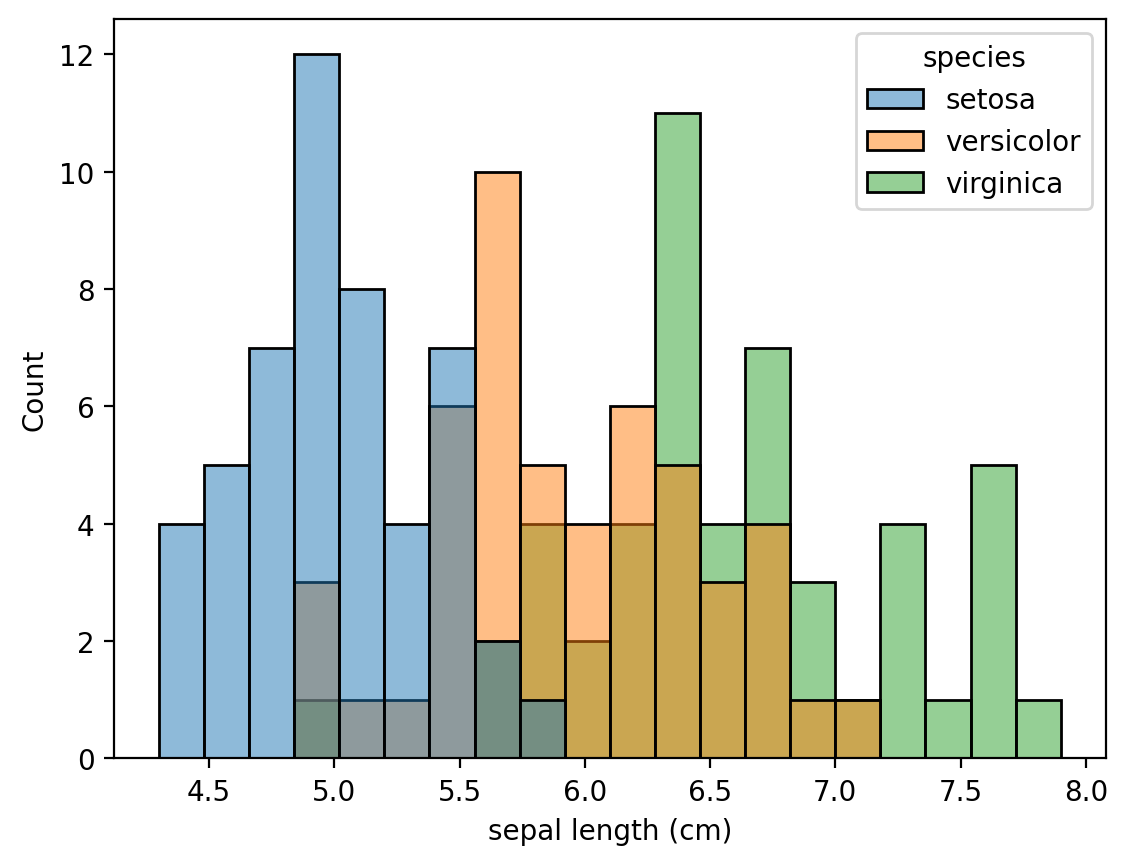
Изначально этот датасет создавался для доказательства возможности классификации цветка к определенному виду без экспертного заключения, опираясь только на количественные параметры цветка. Мы с вами тоже попробуем статистически различить виды по параметрам цветков. Для начала необходимо определить вид распределения в каждой группе (виде растения): подчиняется ли он нормальному закону или нет. Исходя из результатов проверки, мы будем применять те или иные статистические критерии.
Статистические критерии работают от противного, так как обычно только для случая отсутствия эффекта можно подобрать вычисляемое распределение статистики.
С текущим развитием вычислительной техники нам ничего не мешает посчитать любой статистический критерий для любого набора данных. Но тогда встает вопрос о мощности критерия (1 - верояность ошибки второго рода, пропуска цели) и корректности сделанных выводов. Каждый критерий имеет свои допущения, в пределах которых он может корректно работать. Например, для самого известного теста на проверку разницы средних в двух группах, t-теста Стьюдента существуют следующие допущения.
Для проверки на соблюдения нормального закона распределения существует тест Шапиро-Уилка. Применить его очень просто.
res = stats.shapiro(setosa["sepal length (cm)"])
resShapiroResult(statistic=np.float64(0.977698549796646), pvalue=np.float64(0.4595131499174534))Объект с результатами теста содержит значение статистики и p-value, по которому мы определяем значимость результата.
species = iris_df["species"].unique()
parameters = iris_df.columns[0:-1]
pvalue = {}
for s in species:
for p in parameters:
df = iris_df.loc[iris_df["species"] == s, p]
res = stats.shapiro(df)
pvalue[f"{s}_{p}"] = res.pvalue
print(pvalue){'setosa_sepal length (cm)': np.float64(0.4595131499174534), 'setosa_sepal width (cm)': np.float64(0.27152639563455816), 'setosa_petal length (cm)': np.float64(0.0548114671955363), 'setosa_petal width (cm)': np.float64(8.658572739428681e-07), 'versicolor_sepal length (cm)': np.float64(0.4647370359250263), 'versicolor_sepal width (cm)': np.float64(0.3379951061741378), 'versicolor_petal length (cm)': np.float64(0.15847783815657573), 'versicolor_petal width (cm)': np.float64(0.027277803876105258), 'virginica_sepal length (cm)': np.float64(0.25831474614079086), 'virginica_sepal width (cm)': np.float64(0.18089604109069918), 'virginica_petal length (cm)': np.float64(0.10977536903223506), 'virginica_petal width (cm)': np.float64(0.0869541872909336)}Уровень значимости 0.05 подразумевает 1 ложное срабатывание на 20 попыток применения теста, поэтому мы имеем далеко непризрачный шанс получить ошибку. Данная проблема называется проблемой множественных сравнений и её решают корректированием массива p-value. Одна из самых частых применяемых поправок - поправка Бенджамини-Хохберга, более известная как поправка на частоту ложных открытий (false discovery rate, fdr). Применим её к нагему массиву p-value.
adj_res = stats.false_discovery_control(list(pvalue.values()))
print(adj_res.round(4))[0.4647 0.362 0.2192 0. 0.4647 0.4056 0.3101 0.1637 0.362 0.3101
0.2635 0.2609]Тесты на проверку равенства дисперсий: F-тест Фишера и тест Бартлетта оставляю на самостоятельное изучение. Попробуем применить t-тест Стьюдента для произвольного параметра и двух видов.
setosa_sepal_length = iris_df.loc[iris_df["species"] == "setosa", "sepal length (cm)"]
versicolor_sepal_length = iris_df.loc[iris_df["species"] == "versicolor", "sepal length (cm)"]
stats.ttest_ind(setosa_sepal_length, versicolor_sepal_length)TtestResult(statistic=np.float64(-10.52098626754911), pvalue=np.float64(8.985235037487079e-18), df=np.float64(98.0))Проинтерпретируйте результат. Правомочны ли мы применять этот критерий для этого параметра и этих групп?
Тема о сравнении среднего в двух группах на самом деле гораздо более дискуссионная и не сводится к простым алгоритмам, как это представлено в прикладных обучающих пособиях по статистике. Классическая теория вероятности говорит нам о том, что допущение о нормальном законе распределения величины в группах не так важно, так как при количестве наблюдений n < 30, мы можем установить характер распределения с большим уровнем ошибки и априорных допущений, а при n > 30 распределение Стьюдента хорошо аппроксимируется нормальным распределением вследствие Центральной Предельной Теоремы. Несмотря на то, что критерии Манн-Уитни и Вилкоксона преподносятся как непараметрические аналоги t-теста Стьюдента, они проверяет несколько иные нулевые гипотезы. Автор призывает вас не верить слепо гайдам по прикладной биостатистике, и знать как работают используемые в вашей работе критерии.
numpy - мощная библиотека для работы с массивами объектов (не ограничивается только числами). Она работает гораздо быстрее, чем обычные списки, потребляет меньше памяти и предоставляет широкий функционал для работы с массивами любой размерности. На этой библиотеке построены более продвинутые библиотеки для научных вычислений и анализа данных: pandas и scipy. Старайтесь использовать масссивы numpy для ускорения работы вашего кода.
pandas - библиотека для работы с таблицами
Она может читать практически любой формат данных и сохранять в практически любом формате.
pandas позволяет проводить гибкие операции фильтрации по именам, индексам, условиям.