21 Параллельное выполнение инструкций. Многопроцессность vs многопоточность.
21.1 Рекомендуемая литература
- Лекция №10
- Python parallel programming cookbook, главы 1-3.
- Примеры с Хабра
21.2 Цели и задачи
Целью данной работы является изучение особенностей многопоточного и многопроцессного кода. Для достижения поставленной цели необходимо решить следующие задачи:
- Освоить написание многопоточного кода с синхронизацией
- Освоить написание многопроцессного кода с синхронизацией.
- Сравнить производительность многопоточного и многопроцессного кода
21.3 Ход работы
21.3.1 Описание задания
- Создайте программу, которая считывает последовательности из FASTA-файла.
- Реализуйте поиск и подсчет аминокислот по разным физико-химическим классам: гидрофобные, гиброфильные нейтральные, гидрофильные положительные, гидрофильные отрицательные. В случае, если встречаются символы, отличные от стандартного алфавита аминокислот, либо фильтруете запись, либо считаете такие отдельной графой (на ваш выбор). Подробнее на Figure 21.1
- Используйте сначала многопоточность, затем многопроцессность для параллельного анализа последовательностей.
- Обеспечьте синхронизацию потоков/процессов при подсчете общего количества найденных кодонов.
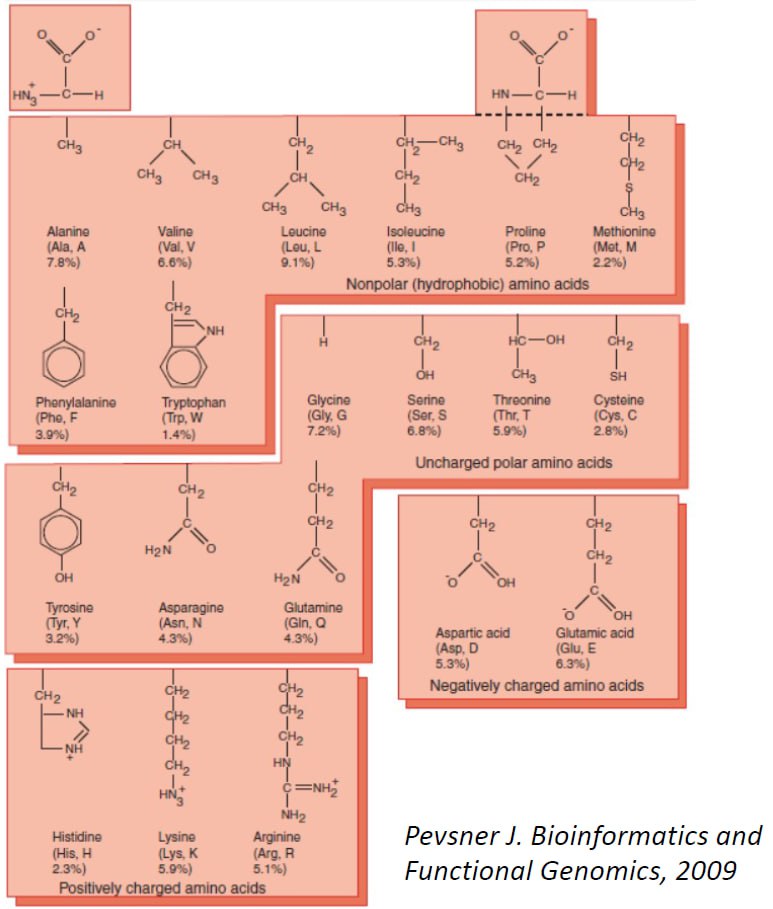
21.3.2 Подготовка к выполнению
Тщательно документируете свои действия и результат!
- Нам необходим тестовый пример. Скачайте тестовый пример последовательностей любого понравившегося белка с базы данных Uniprot. Смотрите, чтобы количество последовательностей было больше 100000.
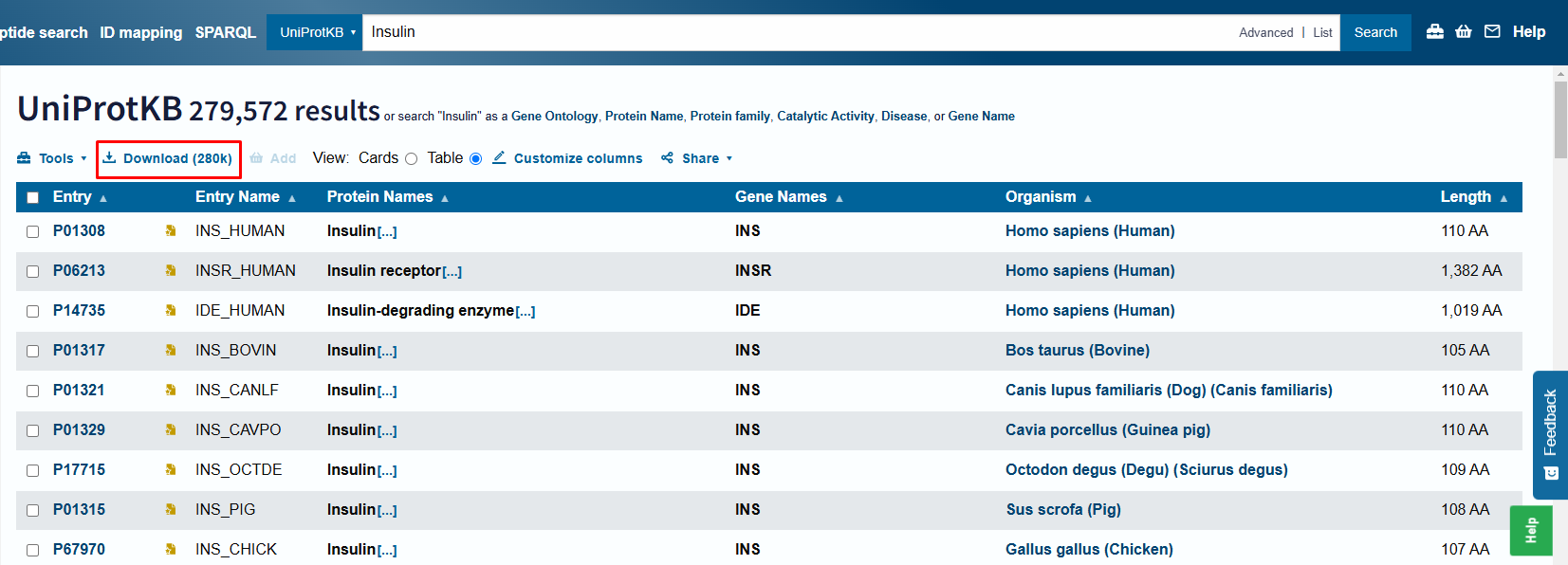
На Figure 21.2 показано, на примере белка инсулина, как можно скачать все последовательности: ничего не выбирая нажать кнопку download. Затем выбрать формат fasta. Для увеличения скорости скачаивания рекомендую выбрать сжатый формат, но для работы тогда нам необходимо её разархивировать.
Доп. задание (необязательно): реализуйте этот этап целиком на Python, с использованием REST API Uniprot и из генератора URL запросов
Возьмите несколько небольших частей этого файла и сохраните в отдельные файлы. Это будут простые тестовые примеры. Подготовьте разного размера - 100,1000, 10000.
Для работы с fasta файлами рекомендую установить библиотеку biopython. Хороший учебник с примерами
conda install -c bioconda biopython21.3.3 Шаги для решения задачи
- Необходимо прописать логику программы в однопоточном режиме. Рекомендую реализовывать её в объектно-ориентированной парадигме. Таким образом вам потребуется класс ProteinAnalyzer, который умеет читать fasta файлы, подсчитывать нужную статистику и сохранять её. Чтение fasta файла с помощью библиотеки biopython можно производить следующим образом.
from Bio import SeqIO
for seq_record in SeqIO.parse("ls_orchid.fasta", "fasta"):
print(seq_record.id)
print(repr(seq_record.seq))
print(len(seq_record))Запись из fasta файла становится объектом класса SeqRecord, который содержит объект класса Seq (seq_record.seq). С таким объектом можно работать как с обычной строкой. Примеры
Проверьте как ваш код работает на маленьких примерах в однопоточном режиме. Проверьте сначала ваш код на маленьких примерах. Используйте модуль time для измерения работы программы.
После проверки в однопоточном режиме, приступайте к реализации многопоточного поведения. Вам потребуется синхронизирующая очередь. Крайне полезны могут оказаться примеры из книги(с.83). Проверьте сначала ваш код на маленьких примерах. Используйте модуль time для измерения работы программы.
Используя примеры из книги(с.113-114), реализуйте многопроцессную реализацию. Проверьте сначала ваш код на маленьких примерах. Используйте модуль time для измерения работы программы.
Постройте график зависимости времени выполнения программы от количества входных последовательностей в разном режиме работы программы при фиксированном, не очень большом количестве потоков/процессов. Сделайте выводы.
Постройте график зависимости времени выполнения от числа потоков, процессов при большом входном файле фиксированного размера. Сделайте выводы.
Предложите оптимальный подход из предложенных с обоснование и способы улучшения вашей реализации.
21.4 Вопросы для защиты
- Что такое поток? Что такое процесс?
- Таксономия Флинна
- Модели организации памяти.
- Виды параллелизма
- Оценка работы параллельного кода
- Механизмы синхронизации между потоками и процессами.